I’ve been doing new experiments analyzing the results of using the microphones without a pipe for resonance. I was expecting flatter results with less noise because of the removal of the resonator. What I found was a lot different.

There were two directions that my search took. One was to run the same geometric configuration with identical input signals or two that are only different in volume. The other direction was to use different speakers to help tease out what effects are by the frequency response of the microphone, the frequency response of the speakers and variation caused by echoes in my work area.
My audio source was a pure tone swept linearly between 40 Hz and 8000 Hz over a timespan of 4, 8 or 12 minutes. Because the sweep is linear, the right half of each graph covers about one octave while the left half shows about ten. That would indicate that I’m emphasizing only a small part of the sound spectrum. I started working with a linear sweep to show as many resonance peaks as I could. That led to that emphasis.
The first effect I found was that the same configuration creates the same signal. I thought that the oscillating waveforms would an effect of random noise. The surprising part is that although it looks like a noisy waveform, it’s a reproducible and pretty consistent.
This graph shows two runs with the same speaker and microphoone in the same geometry but different volume input signal. There were minimal adjustment to get the graphs to line up. However, if they lined up perfectly, there would be no blue.
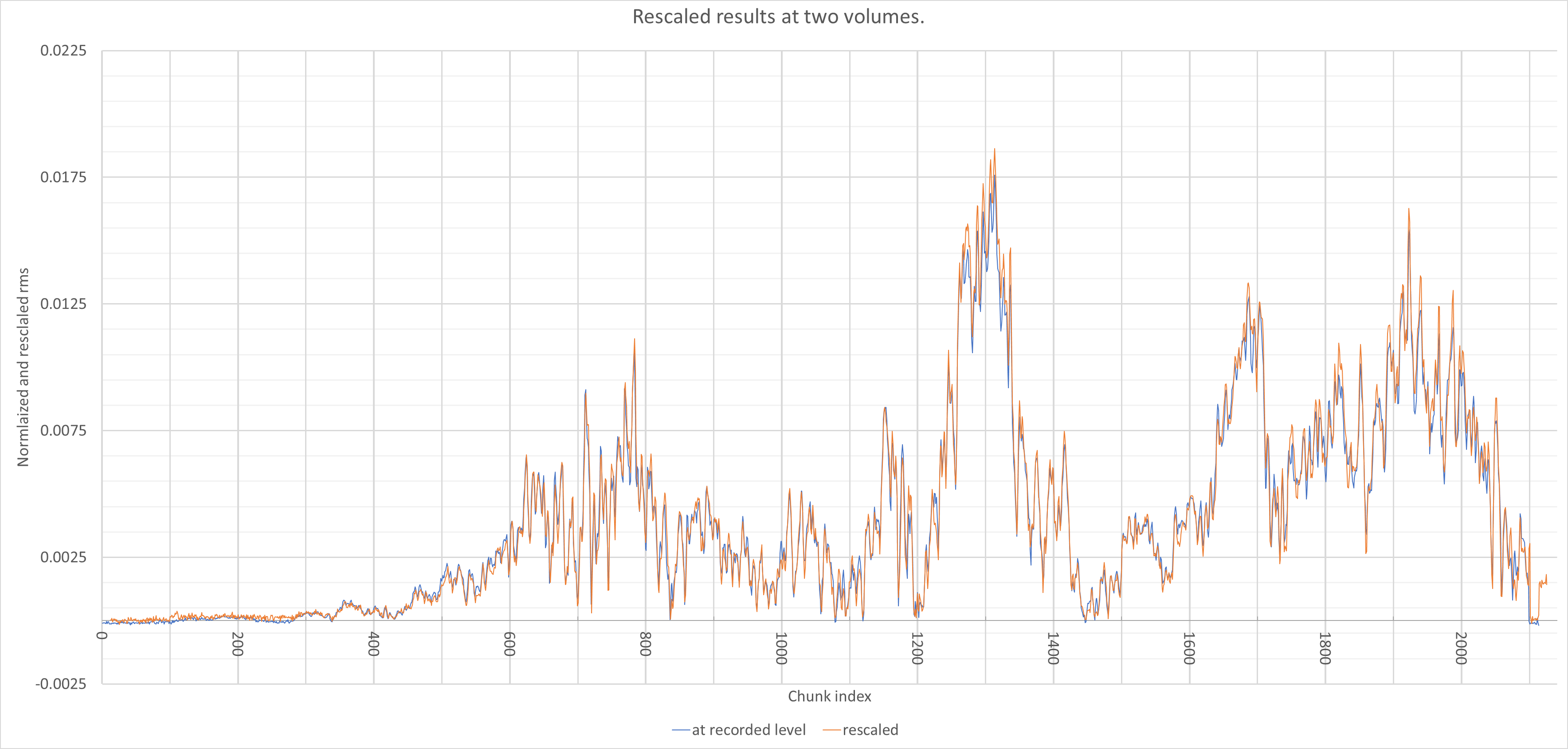
One interesting measurement is that temporally stretching the sweep into different duration scans also have a similar consistency in different runs.
The way I get these graphs is to record the microphone and then break the waveform into short chunks that are delimited by zero crossings of the signal. Each chunk has its samples squared and the square root of the average recorded.
Although the graph above looks pretty noisy, because the graph is consistent, there’s more going on. I performed the same chunking with the raw input signal below. There is a little noise, but it is substantially smaller than the variations in the above signal.
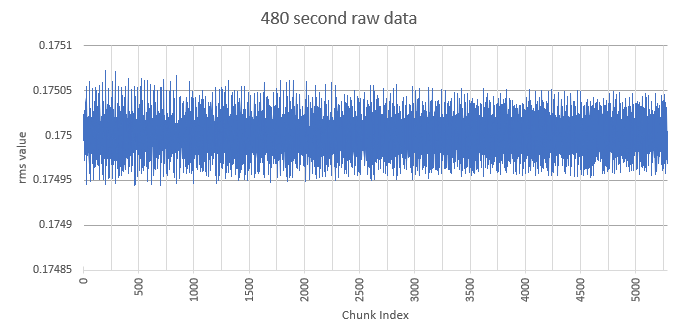
The x axis of each graph is indexed by the chunks in sequence.
The other question that I would like to answer is the manner that the speaker or microphone have different frequency response curves. I took three speakers that I have and ran the same input sequence. I couldn’t get the geometry of the speakers identical between the runs, so the effects of reflections off objects in the room are an unexplored effect.
What I saw when I analyzed the graphs and placed them together is that there is a big variation in the sounds recorded from each speaker. I don’t see anything that is obviously due to distortion from the microphone. I can’t say that it isn’t there but the effects of the geometry and the difference between the speakers appear to swamp any effect of the microphone.
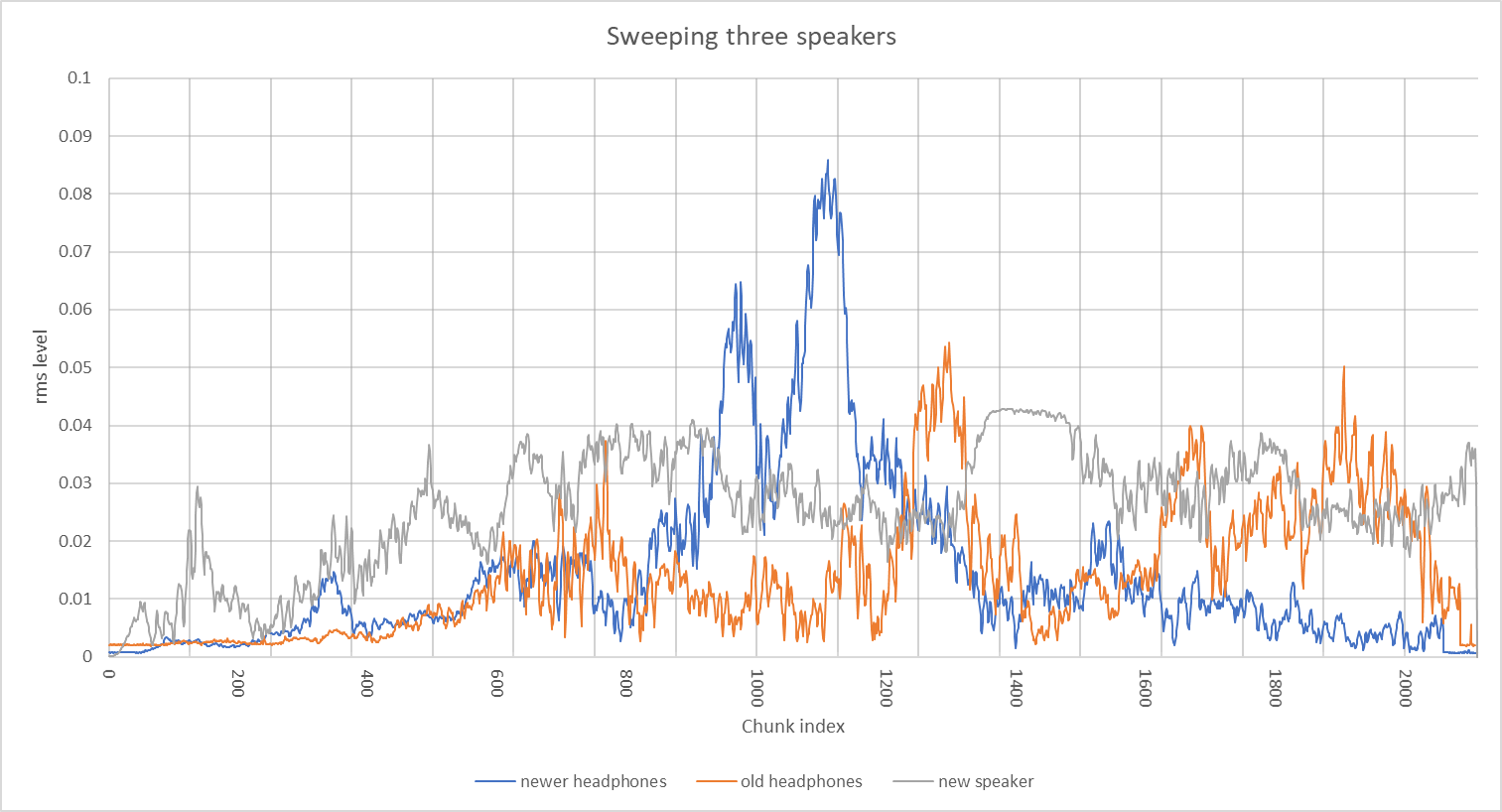
I’d like to do more work exploring the effects of changing the geometry on the results as well as trying to identify the frequency response of each part of the system, microphone, speaker and room configuration. I’m not confident that I have enough data streams available to separate them.
One thing I learned is that making recordings during the day is fraught because of noisy traffic, construction work or lawnmowers. In the evening, the external noise sources are much lower. Another thing I learned is that collecting this data is time consuming. Each run takes 4 – 8 minutes which adds up.
One goal is to make some jigs so that I can reproduce the geometry from one day to the next.
